
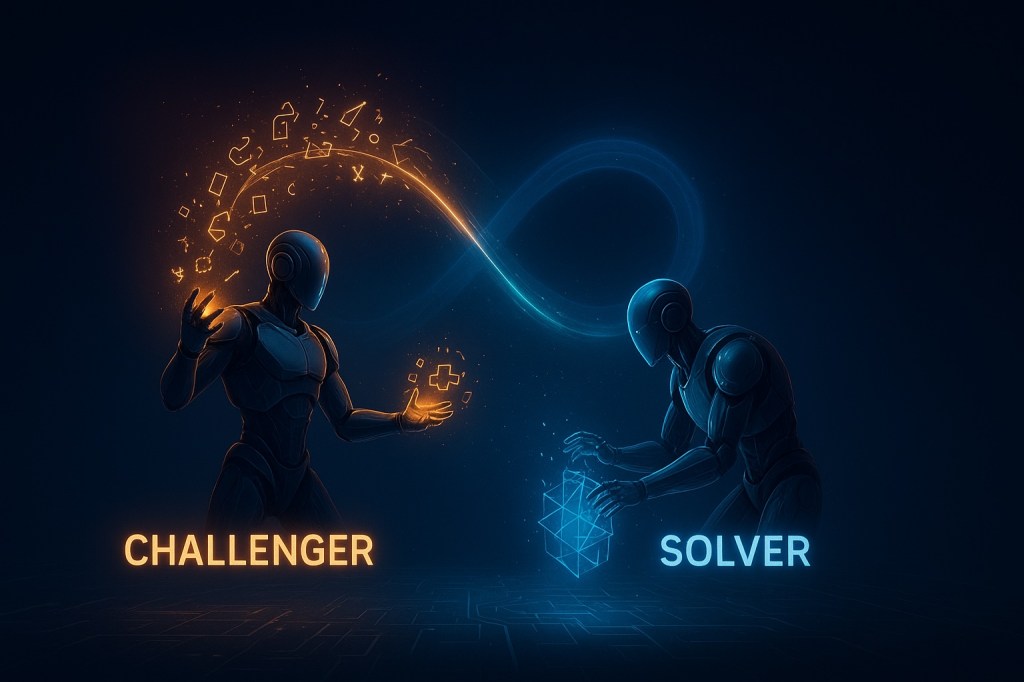
Researchers from Tencent AI Lab and Washington University in St. Louis have introduced a new training framework named R-Zero, which enables large language models (LLMs) to enhance their capabilities without relying on human-labeled data. This framework employs reinforcement learning to generate its own training data, addressing a significant barrier in the development of self-evolving AI systems. R-Zero operates through two independent models that challenge and evolve alongside one another.
Preliminary experiments indicate that R-Zero can notably improve reasoning abilities across various LLMs, potentially reducing the complexity and costs associated with training advanced AI. This method may facilitate the rapid development of specialized models for complex reasoning tasks, alleviating the traditionally high expense of curating labeled datasets.
Self-evolving LLMs aim to develop AI systems that can autonomously refine and learn from their experiences. However, such systems often require extensive high-quality tasks and labels, which typically demand human input that is expensive and time-consuming. Researchers have been exploring label-free methods using models’ outputs to create reward signals but acknowledge limitations in their applicability across truly self-evolving scenarios.
The R-Zero framework divides a base model into two roles: a “Challenger” that generates tasks and a “Solver” that attempts to complete them. The Challenger creates problems that are optimally challenging, while the Solver is rewarded for successfully addressing these tasks. When the Challenger generates high-quality questions, the Solver’s training improves significantly, indicating the importance of the Challenger’s role in crafting a robust learning environment.
Testing of R-Zero has shown effectiveness across several open-source LLMs. For example, the Qwen3-4B-Base model demonstrated an average score improvement of +6.49 in math reasoning benchmarks after utilizing R-Zero. However, a decline in the accuracy of self-generated labels—dropping from 79% to 63%—raises concerns about data quality in subsequent iterations. Researchers recognize maintaining stable, long-term improvements as a critical challenge.
For broader applications beyond mathematical logic, including subjective tasks like marketing or report summarization, a suggested direction involves introducing a “Verifier” model to provide quality assessments. This system of three co-evolving agents might enhance the overall effectiveness of AI in mastering more complex reasoning tasks.
Source: https://venturebeat.com/ai/forget-data-labeling-tencents-r-zero-shows-how-llms-can-train-themselves/